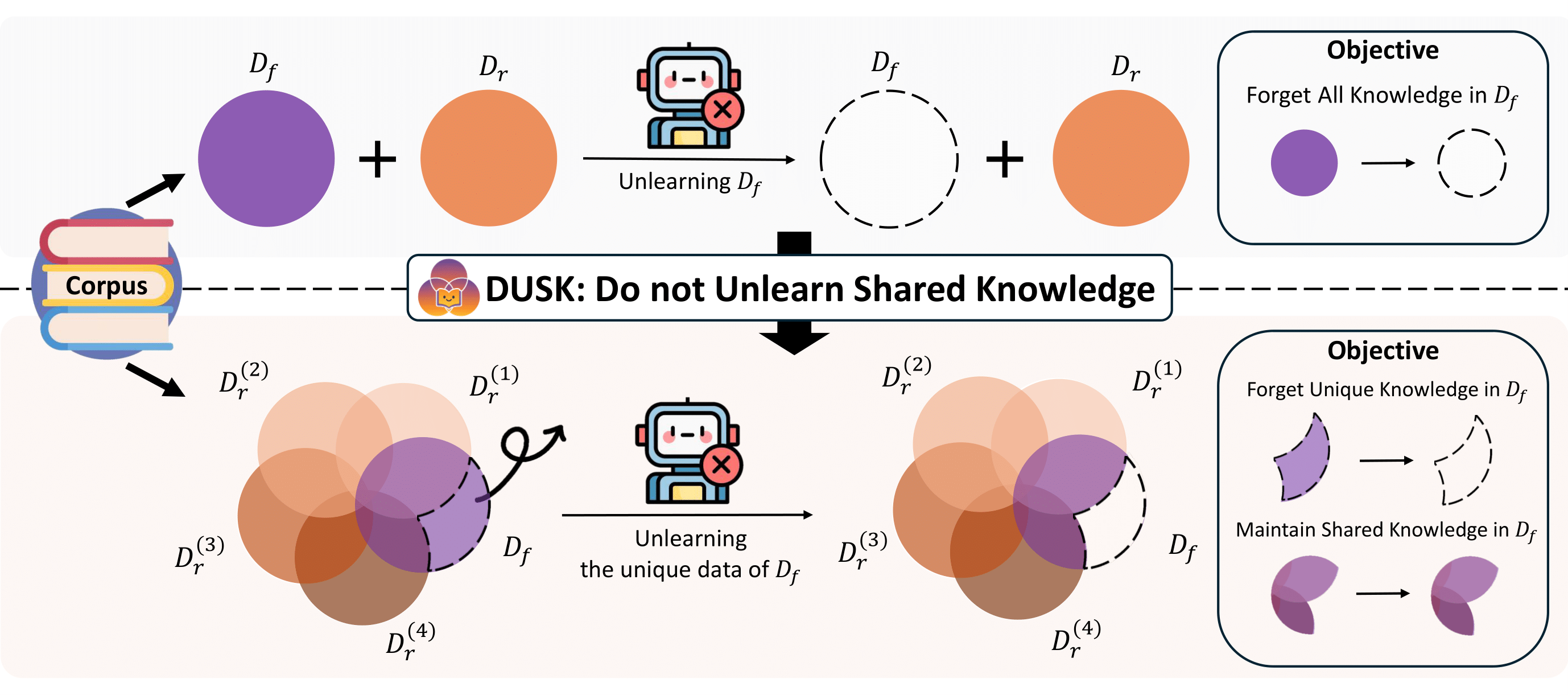
Machine unlearning aims to remove the influence of specific data from a trained model, often in response to privacy regulations or user deletion requests. While prior benchmarks typically assume that the forget set and retain set are disjoint in both data and content, real-world deletion requests often involve documents that contain a mixture of private and general knowledge. Simply forgetting entire documents in these cases can lead to unintended removal of shared information that should be preserved.
However, existing benchmarks fail to capture this critical overlap, limiting their ability to evaluate selective forgetting in practical scenarios.
To address this, we introduce
 DUSK, a new benchmark that explicitly models overlap between forget and retain sets.
DUSK provides a controlled synthetic corpus of documents with clearly separated unique and shared content, enabling fine-grained evaluation.
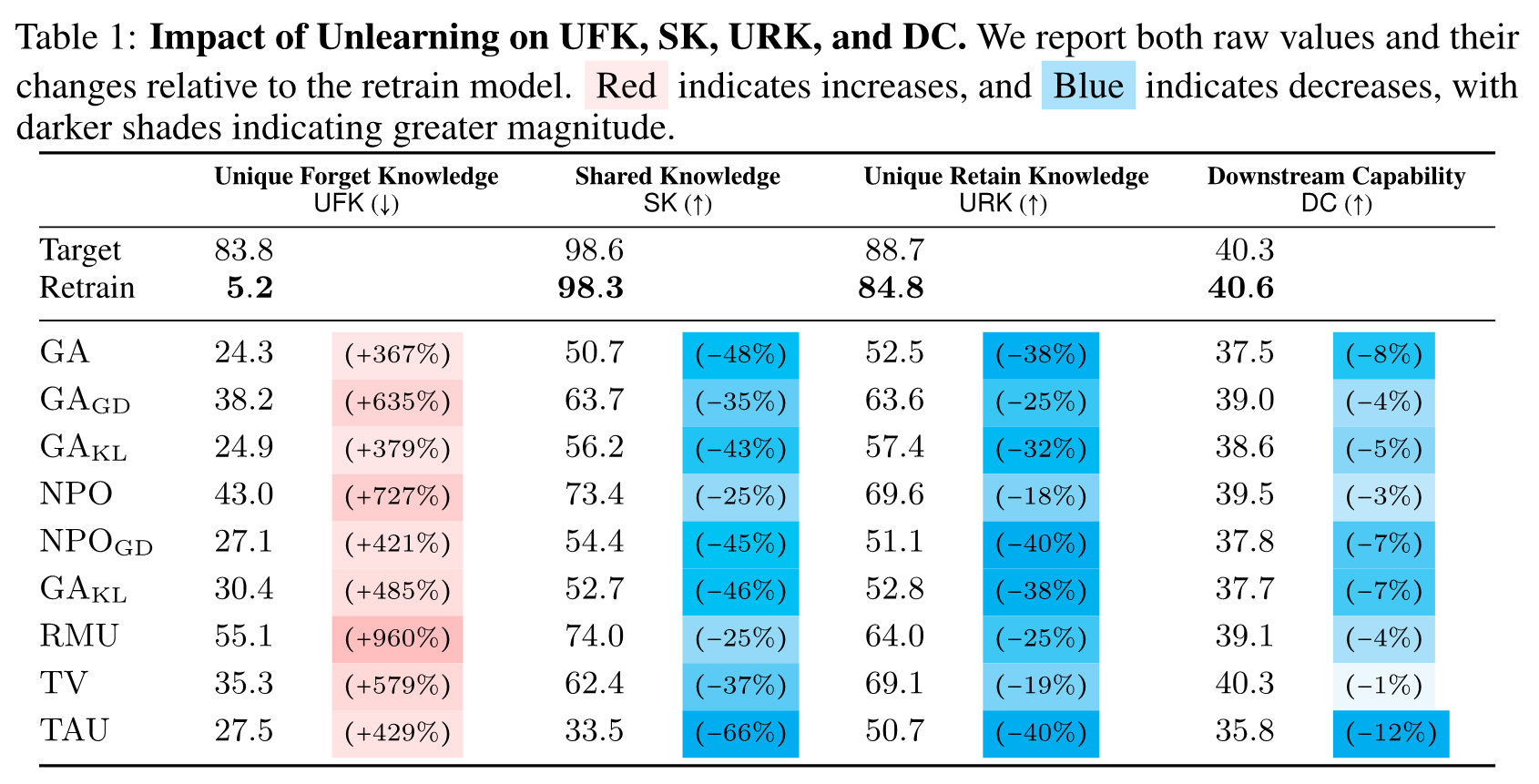
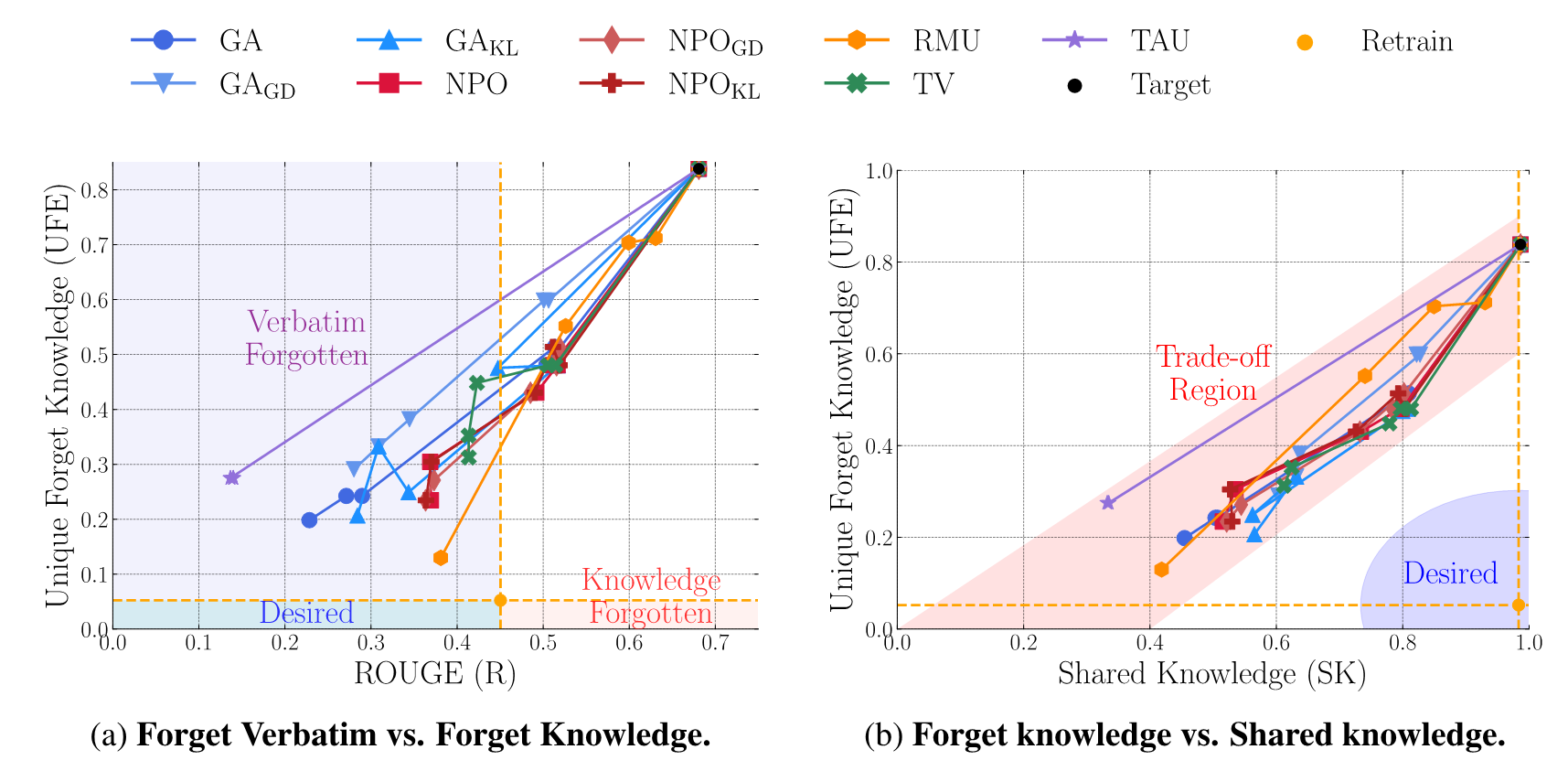
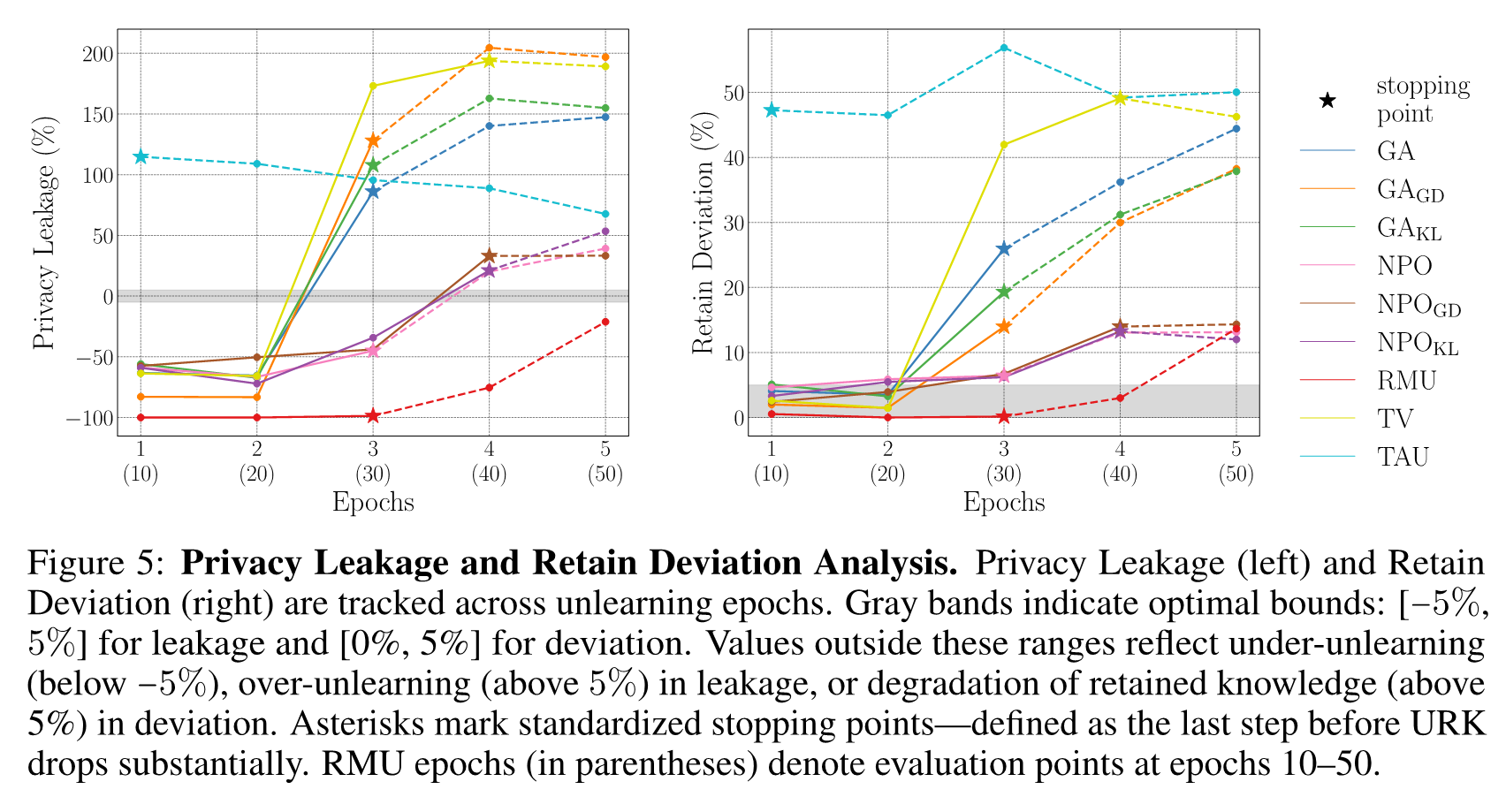
We propose comprehensive evaluation metrics that jointly assess forgetting effectiveness, retention of shared and retain-specific knowledge, preservation of downstream capabilities, and privacy leakage.
Through experiments across nine unlearning methods, we reveal fundamental trade-offs between effective forgetting and utility preservation, demonstrating that achieving both remains a significant challenge.
DUSK, a new benchmark that explicitly models overlap between forget and retain sets.
DUSK provides a controlled synthetic corpus of documents with clearly separated unique and shared content, enabling fine-grained evaluation.
We propose comprehensive evaluation metrics that jointly assess forgetting effectiveness, retention of shared and retain-specific knowledge, preservation of downstream capabilities, and privacy leakage.
Through experiments across nine unlearning methods, we reveal fundamental trade-offs between effective forgetting and utility preservation, demonstrating that achieving both remains a significant challenge.