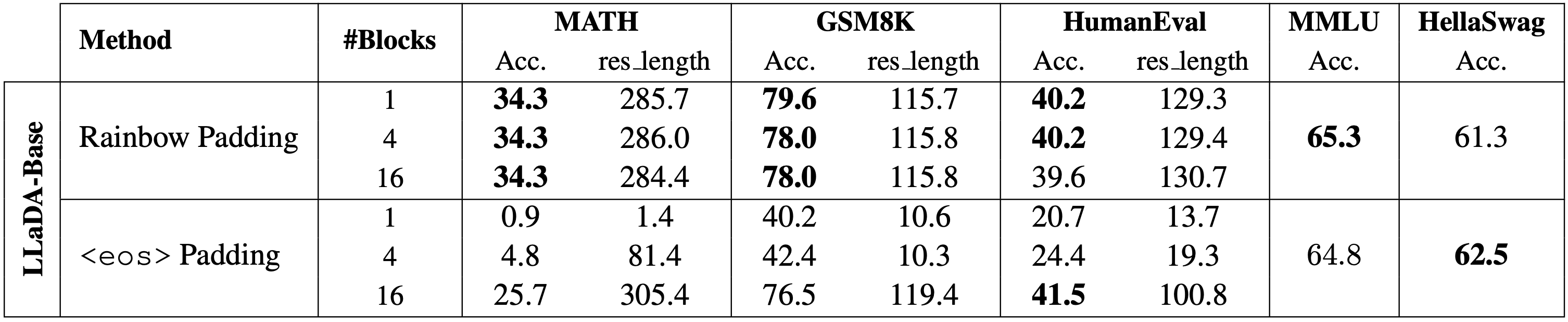
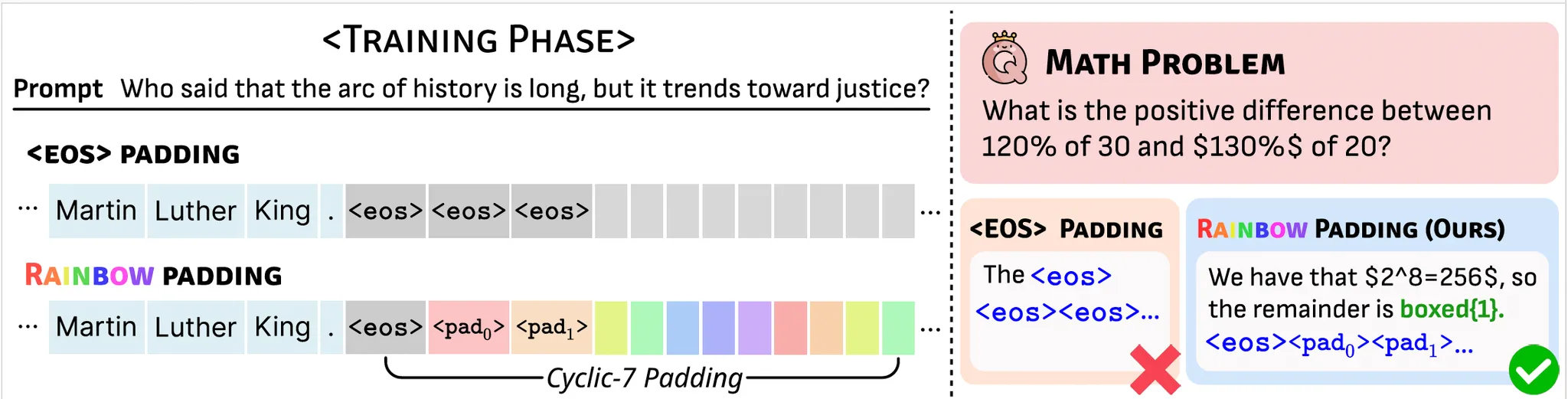
To prevent probability mass from concentrating on a single token, we propose Rainbow
Padding.
The true response end uses a single <eos> token, while remaining positions are filled
with a cyclic sequence of K distinct padding tokens:
$$ \mathcal{P}=\{\texttt{\langle pad_0\rangle},\,\texttt{\langle pad_1\rangle},\ldots,\,\texttt{\langle
pad_{K-1}\rangle}\}. $$
This distributes probability mass evenly across multiple padding tokens,
reducing individual confidence. Under adaptive decoding strategies, no single padding token has high enough
probability for early selection,
effectively mitigating early termination.