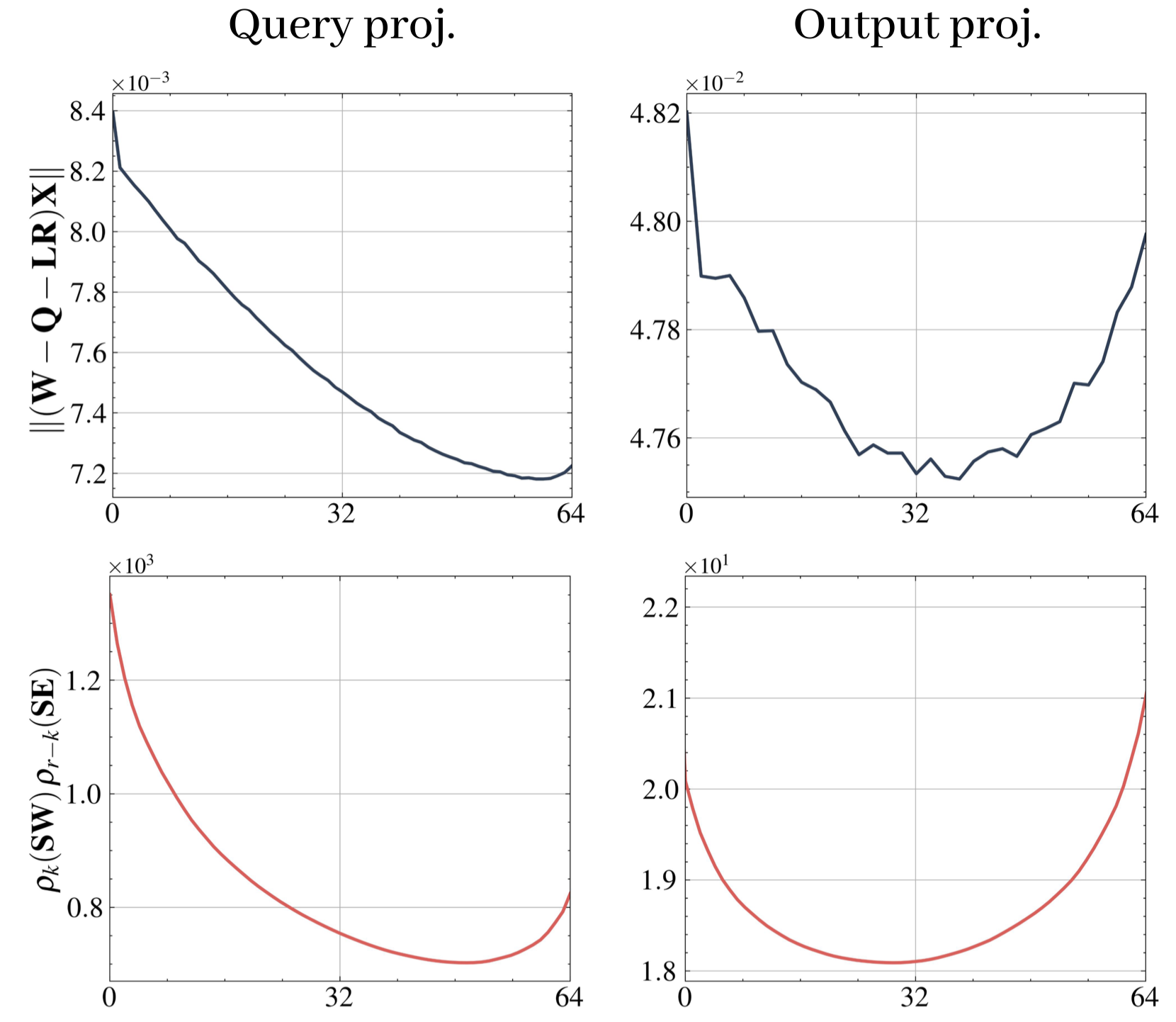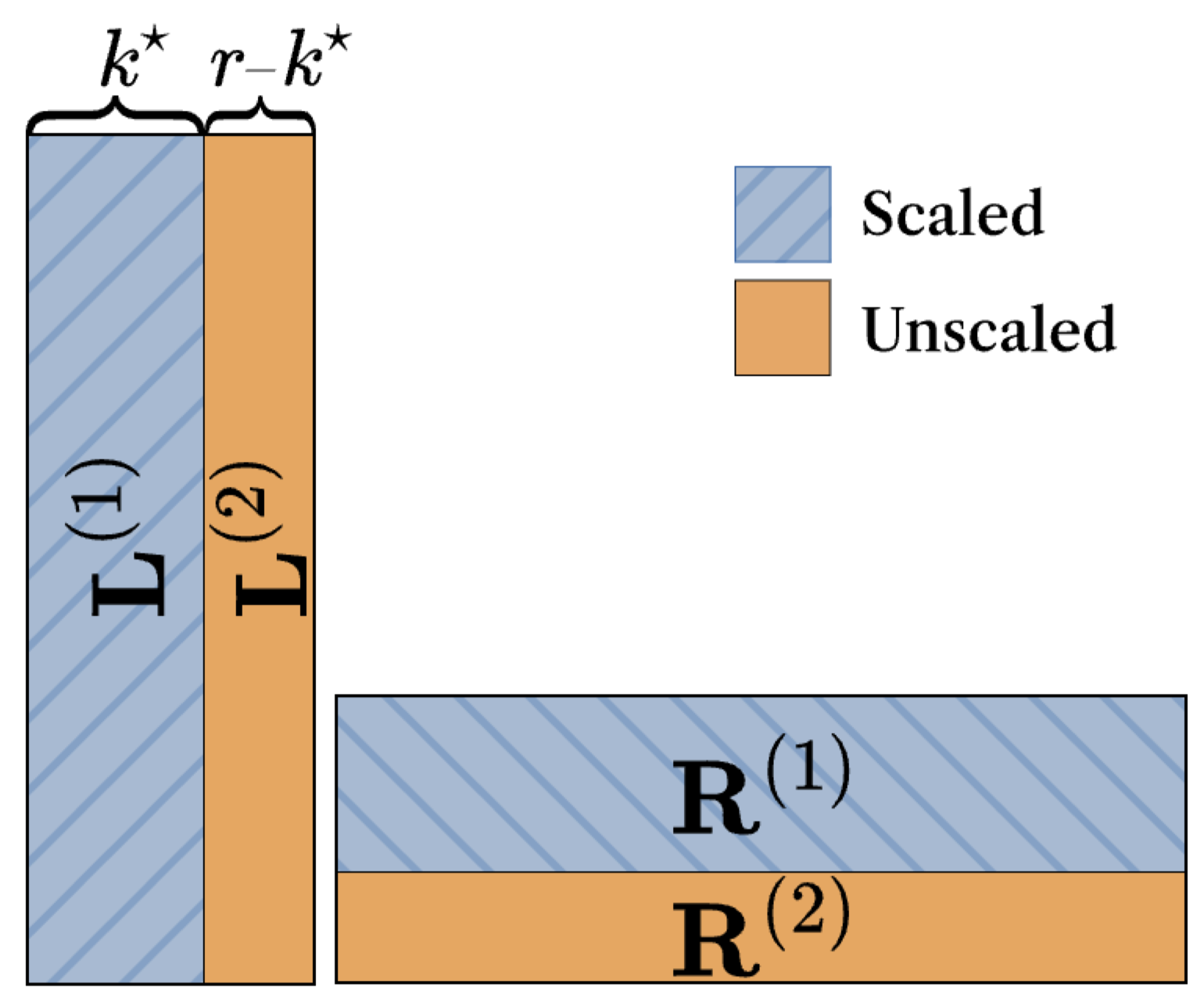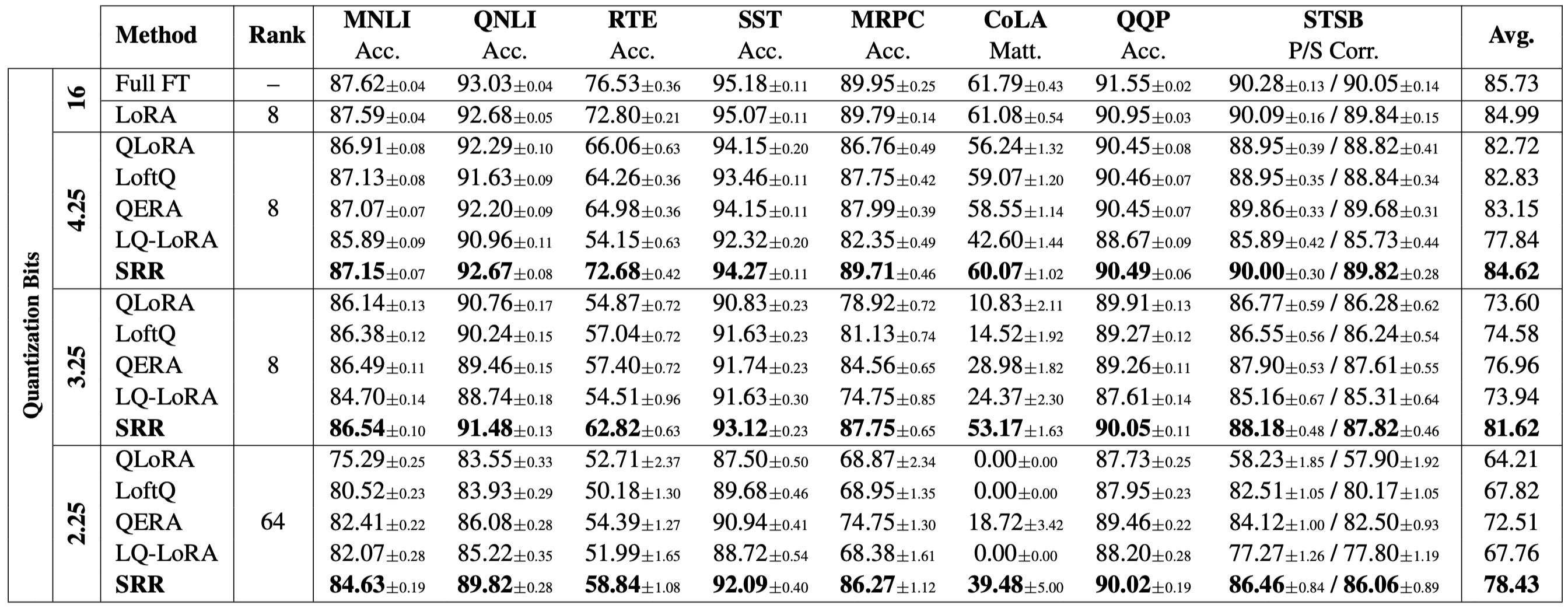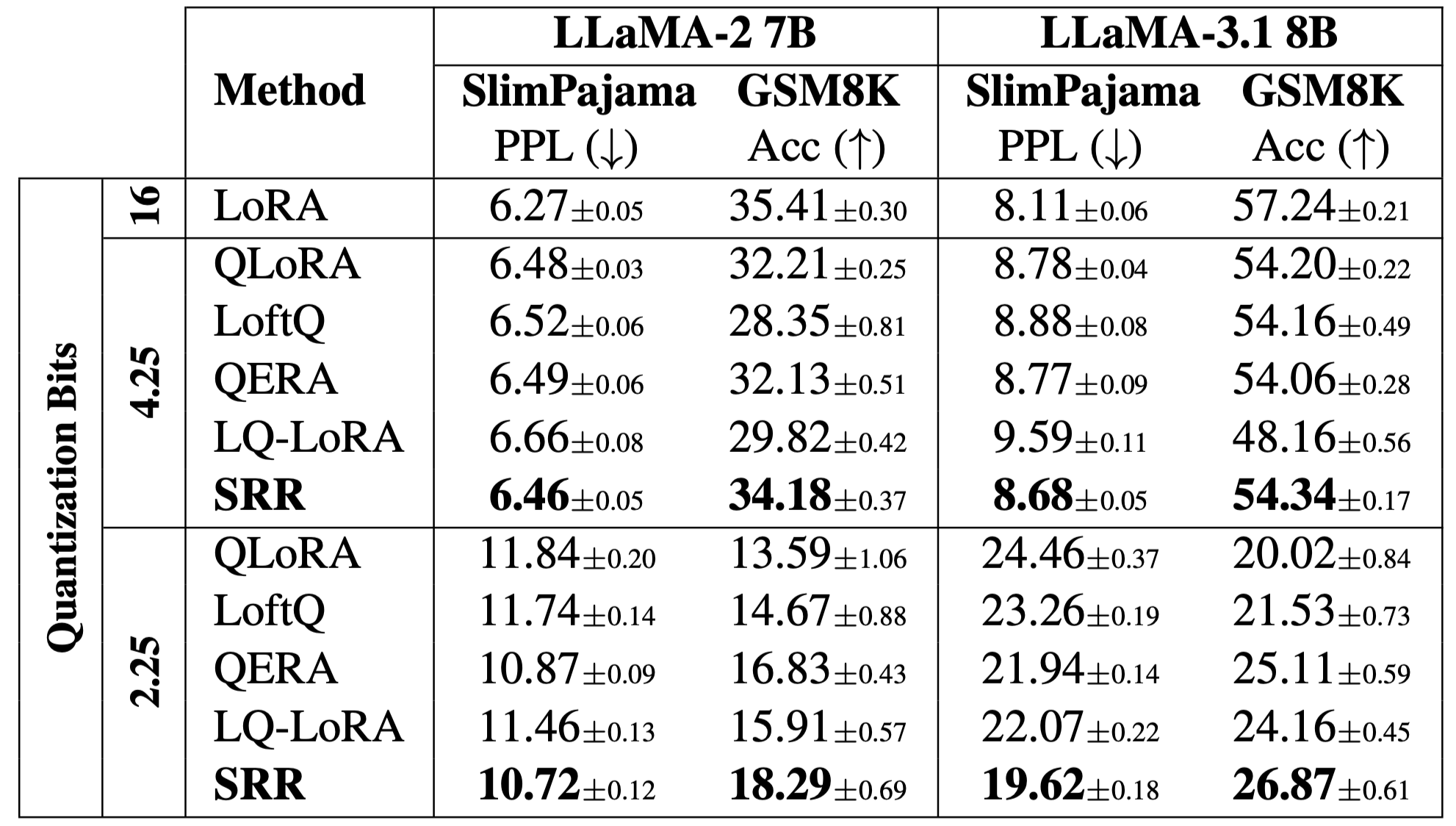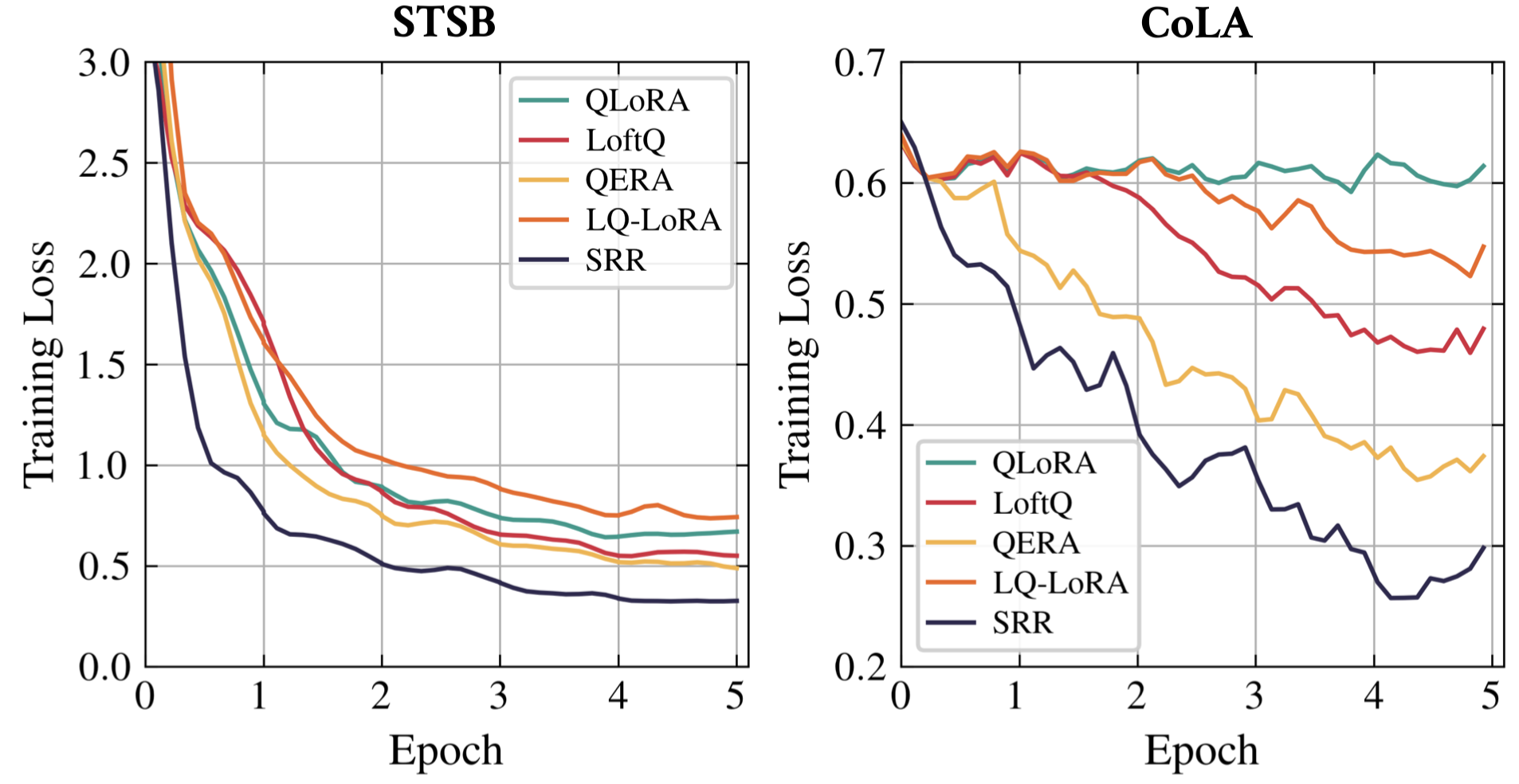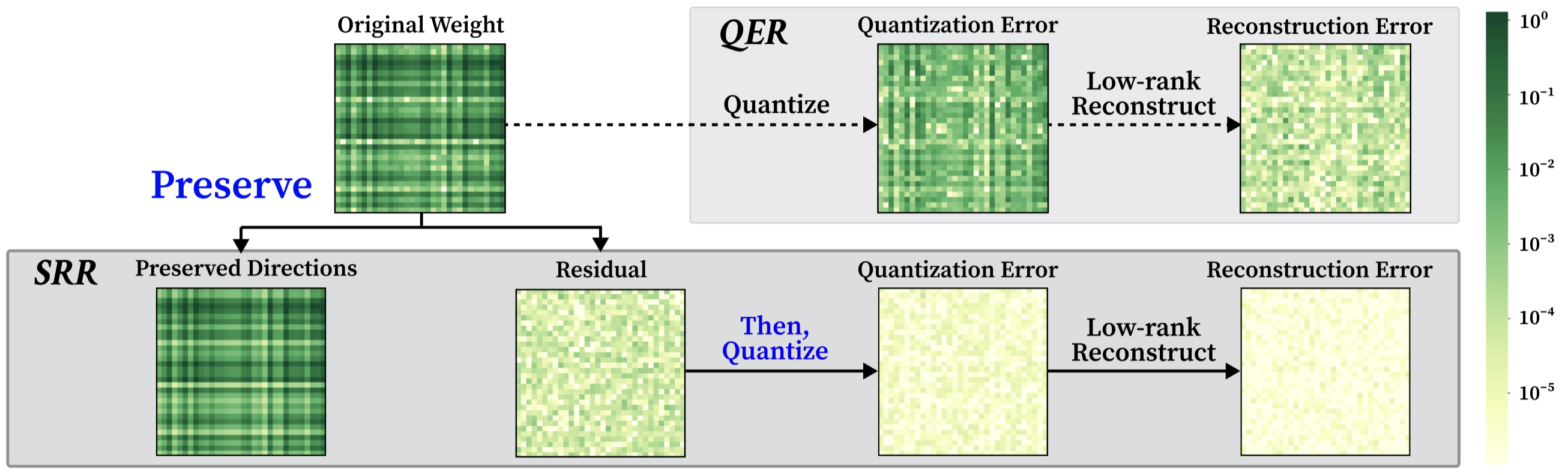
The SRR Pipeline
Given a rank budget $r$ and a split $k\in\{0,\ldots,r\}$, SRR proceeds in three steps:
- Preserve. Take the top-$k$ singular components of the scaled weight
$\mathbf{SW}$ and map them back to the original space:
$$ \mathbf{L}_k^{(1)}\mathbf{R}_k^{(1)} \;:=\; \mathbf{S}^{-1}\,\mathrm{SVD}_k(\mathbf{SW}). $$
- Quantize the residual. Apply the base quantizer $\mathcal{Q}$ to what
remains, and let $\mathbf{E}_k$ denote the resulting error:
$$ \mathbf{Q}_k \;:=\; \mathcal{Q}\bigl(\mathbf{W}-\mathbf{L}_k^{(1)}\mathbf{R}_k^{(1)}\bigr),\qquad \mathbf{E}_k \;:=\; \mathbf{W}-\mathbf{L}_k^{(1)}\mathbf{R}_k^{(1)}-\mathbf{Q}_k. $$
- Reconstruct. Use the remaining $r-k$ ranks to fit the quantization error
$\mathbf{E}_k$ in the scaled space:
$$ \mathbf{L}_k^{(2)}\mathbf{R}_k^{(2)} \;:=\; \mathbf{S}^{-1}\,\mathrm{SVD}_{r-k}(\mathbf{SE}_k). $$
The final approximation
$\widehat{\mathbf{W}}_{\mathrm{SRR}}(k) = \mathbf{L}_k^{(1)}\mathbf{R}_k^{(1)} + \mathbf{Q}_k +
\mathbf{L}_k^{(2)}\mathbf{R}_k^{(2)}$
folds into the standard QER form $\widehat{\mathbf{W}} = \mathbf{Q} + \mathbf{LR}$.
SRR is therefore drop-in compatible with any quantizer and preserves the standard
QER formulation.